CRAC is based on the classical MPI triplet: daemon, application,
spawner. The daemon is launched on each machine constituting the
Virtual Distributed Machine (VDM). The user develops its
application and launches it with the spawner on the desired machines.
However, the similarity with MPI nearly stops here. Even if the CRAC
programming interface uses the message passing paradigm, the semantic
of communications is completely different and several primitives do
not exist in MPI. Furthermore, the internals of CRAC are based on
multi-threading and even the application is a thread. Finally, the
virtual distributed machine relies on a hierarchical view of the
network in order to reach machines with private IPs and to limit the
bandwidth use on slow links.
The following sections present the different components of CRAC: VDM, Daemon, Tasks and Spawner.
The efficiency problem of distributed executions partly comes from
"low" bandwidth on links between distant geographical sites. In this
case, a primitive like a gather-scatter that does not take care of the
network architecture may be totally inefficient if all messages must
take the slowest link of the architecture. Assuming that machines can
be gathered in "sites", which have good bandwidth, and that sites are
linked by "low" bandwidth, all global communications may be optimized
to take account of this organization. This is the case when the
architecture is composed of clusters linked by the Internet.
Unfortunately, cluster machines often have private IPs and can be
reached only through a frontal machine. To get round this problem,
the frontal may relay messages.
MPI does not take into account the network architecture but CRAC does.
Thus we can give the following definition of "site" as a pool of
machines that can directly connect to one another. This notion is not
necessarily geographical but this may sometimes be the case. For
example, if the machines of two distant clusters can freely
interconnect, it is better to separate them in two sites if the
bandwidth between the clusters is low. If it is similar to the
bandwidth inside clusters, they can be gathered in the same site.
Within a site, four types of machines are possible: master,
supermaster, slave, frontal. The last type may be
applied to any of the three first. For example, a machine may be a
slave frontal. This characterization allows to optimize the management
of the VDM (starting/stopping the daemons, spawning, ...), and to
reach machines with private IPs. Here is the definition of the
types.
- frontal: a machine that can relay messages from outside the
site to the private IP machines of the site. It can also relay
messages to another site if a machine cannot send outside the
site.
- slave: a machine with no particular role.
- master: a machine that collects informations from the
slaves of the site and relays them to the supermaster, or that
relays informations from the supermaster to the slaves.
- supermaster: a machine that collects/sends informations
from/to the masters. Obviously, the supermaster is a master but is
unique.
The VDM is defined via an XML file, which is a perfect language to
describe its hierarchical organization. This file is passed as an
argument to a booter (like lamboot) that launches the daemons on each
machine of the VDM. Then, a TCP connection is created between each
master and the supermaster, and between each slave and its own master.
This hierarchy allows to limit the bandwidth use between the sites.
For example, when tasks are spawned for an execution, the supermaster
sends the configuration of the execution (the machines used and their
number) to all masters, which relay the information to their own
slaves.
In order to limit the number of connections between tasks, the
convergence detection mechanism also uses this hierarchy. Thus, even
if a master runs no task, its daemon is in charge of collecting the
local convergence state of each task running in the site.
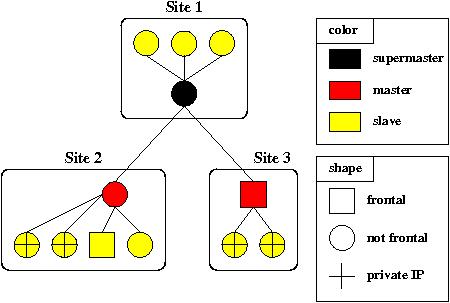
Figure above shows an example of VDM with 3 sites. The lines
represent the TCP connections that constitute the hierarchical network
used for convergence detection and for management (essentially
launching and stopping tasks). In sites 2 and 3, two slaves have
private IPs. Thus, it is mandatory for a machine of this site to be a
frontal. It may be the master itself as in site 3 or simply another
slave, as in site 2. It can be noticed that there are no connections
between masters and that the supermaster may also have slaves, as in
site 1.
During the execution of an application, a task may communicate data
to a task on another machine. The hierarchical network is never used
for that. Instead, a new TCP connection is created between the
machines running the two tasks the first time they want to
communicate.
back to top.
A CRAC daemon is launched on each machine of the VDM. During an
execution, its main use is to send/receive data and convergence state
for the local tasks. If the machine is a frontal, the daemon may also
relay messages to tasks hosted by another daemon. These operations are
executed by three threads: the Sender, the Receiver, and
the Converger.
Multi-threading the communications allows two things that are
essential for an AIAC execution:
- emissions and receptions are non-blocking.
- when the Receiver receives several times the same updating
message before the computing task explicitly calls the reception
routine, the last message always overlap the older (see message crushing paragraph in AIAC).
It can be noticed that the second point is totally transparent for the
user and constitutes a real improvement compared to MPI in which each
received message must be consumed.
A detailed description of each thread may be found in
this article.
back to top.
The application task is a thread that executes within the daemon
context. Thus, the task can directly access message queues (incoming
and outgoing). This is not the case for MPI, in which a task is a
process and must communicate (with an Unix socket or shared memory)
with the daemon to send/receive data. Furthermore, a CRAC daemon may
host several application tasks.
As CRAC is an object environment, the Task class is defined
as a thread, containing all primitives of the programming interface
and the classical attributes of a task (identifier, number of task in
the daemon and in the VDM, ...). CRAC also declares (as an include
file) the UserTask class which inherits from Task. This
class contains a run()
method that must be defined by the user in a C++ file, which is
compiled as a shared library. When a task is launched on a machine
via the spawner, the daemon dynamically loads its code and creates a
new thread object containing this code. The thread is started and its
run() method
automatically called, as in Java.
back to top.
The CRAC spawner is a classical MPI spawner, except that it uses an
XML file to specify which and how many tasks are launched on which
machine. The access path of the code of each task must be given for
each machine. Thus, it is possible to have an MIMD execution. It is
also possible to pass arguments to each task. For now, the spawn is
only static and tasks cannot be added during an execution.
back to top.