Transposition de matrice¶
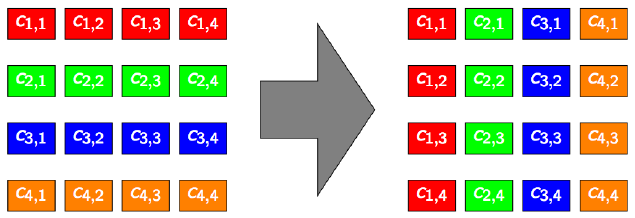
Soit la matrice \(C\) dont les éléments sont notés \(c_{i,j} (i \in [1;H], j \in [1;W])\).
La matrice transposée \(C^{T}\) a pour éléments \(c^{T}_{i,j} = c_{j,i} (i \in [1;W], j \in [1;H])\)
Illustration pour \(H = W = 4\)
Expérimentations
Écrire un kernel CUDA réalisant la transposition parallèle d’une matrice quelconque.
Compléter le programme
mainpermettant d’exécuter le kernel de transposition. Pour mémoire, le main doit a minimaallouer de la mémoire, coté CPU (hôte) pour les données à fournir au GPU (la matrice à transposer).
allouer de la mémoire, coté CPU (hôte) pour ranger la matrice transposée lorsqu’elle aura été calculée par le GPU.
allouer de la mémoire, coté GPU (device) pour les données à fournir au GPU (la matrice à transposer) en provenance du CPU.
allouer de la mémoire, coté GPU (device) pour ranger la matrice transposée lorsqu’elle aura été calculée par le GPU, avant qu’elle ne soit transférée vers le CPU.
générer une matrice à transposer, dont les dimensions pourront par exemple être passées en arguments sur la ligne de commande. Les valeurs des coefficients pourront être aléatoires.
copier la matrice à transposer vers le GPU.
déterminer les dimensions de la grille de calcul à générer pour le kernel.
exécuter le kernel.
copier la matrice transposée vers le CPU.
Note
Une des grandes difficultés du développement pour GPU est la mise au point des programmes.
Dans le cas de la transposée, il est assez facile d’écrire une référence séquentielle pour vérifier la validité du traitement.
Exemple de sortie console :
perrot@cluster3:~$ ./matrixTranspose 1024 1024 Launching kernels ***** Transpose Summary ***** GPU : Tesla K40c Matrix 1024x1024 (float) Data transfer CPU-->GPU in 0.755000 ms Data transfer GPU-->CPU in 2.269000 ms Grid dims : 1040 x 1040 of blocks 16 x 16 Transpose mean time : 4.153509 ms Transpose check : OK CPU time : 20.472000 ms GPU speedup : 4.928845
Optimisations environnementales¶
Plusieurs aspects permettent d’augmenter les performances globales :
Les allocations mémoire coté GPU : l’alignement mémoire permet des accès plus rapides.
Les allocations mémoire coté CPU : lorsque cela est possible, allouer de la mémoire non-paginée (pinned memory) permet d’accroître les taux de transfert CPU<–>GPU.
Les dimensions de la grille (taille des blocs).
L’implémentation du kernel.
Expérimentations (suite)
Il est intéressant d’évaluer les apports, en termes de performance, des optimisations de l’écosystème autour des kernels :
Coté GPU, allouer de la mémoire alignée (mallocPitch) et à effectuer des copies en conséquences (cudaMemcpy2D).
Coté CPU, allouer de la mémoire non-paginée (cudaMallocHost).
Jouer avec la taille des blocs (ils ne sont pas nécessairement carrés). On peut même envisager un auto-tuning brutal qui lancerait des exécutions avec toutes les tailles de blocs possibles pour déterminer la meilleure des configurations.
Optimisations du kernel¶
Le kernel naïf, tel que vraisemblablement écrit dans la première phase d’expérimentation, comporte un point faible majeur : la non contiguïté des accès en écriture.
Pour pallier ce défaut, on se propose d’utiliser la mémoire partagée comme tampon de sorte à pouvoir assurer la contiguïté des accès aussi bien en lecture qu’en écriture.
Expérimentations
Récrire le kernel de transposition en utilisant une zone de mémoire partagée. Pour rappel : les zones de mémoire partagée sont accessible à tous les threads d’un même bloc ; leur taille est limitée à 48K x 4o.
Il y a deux façon de spécifier la taille de la mémoire partagée à allouer :
Dynamiquement, dans le main(), lors de l’appel du kernel, comme troisième paramètre entre les
<<< , , >>>. Dans ce cas.Statiquement, dans le kernel.
Physiquement, la mémoire partagée est dite on-chip donc plus proche du processeur et plus rapide aussi. Toutefois, son implantation est réalisée à l’aide de circuits mémoires pouvant mémoriser des mots de 4 octets. Ces circuits sont au nombre de 32 et on les nomme des banques. Les accès à la mémoire partagée sont ainsi soumis à des contraintes d’implantation qui peuvent, si elles ne sont pas respectées, dégrader considérablement les performances.
Par ailleurs, les contraintes d’accès à la mémoire partagée ne sont pas exactement les même pour toutes les générations de GPUs NVidia. Sur le GPU de la famille Fermi dont dispose l’EC-M (C2050), la contrainte peut s’exprimer ainsi :
L’exécution de threads est ordonnancée par warps de 32 threads. Chaque demi-warp (16 threads) est exécuté par l’un des deux moteurs d’exécution.
Si deux threads n’appartenant pas au même demi-warp tentent d’accéder à des données rangées dans la même banque, alors il y a conflit de banque et les instructions sont alors sérialisées.
Une exception exéiste : le broadcast (diffusion), lorsque tous les threads d’un warp cherchent à lire la même donnée.
Expérimentations
Modifier très légèrement le kernel de transposition de sorte à éviter les conflits de banques en mémoire partagée.
Modifier encore le kernel pour faire en sorte que chaque thread effectue la transposition de plusieurs coefficients. Cela permet de ré-équilibrer un peu le ratio calcul/communications dans ce type de kernels où les calculs sont presque inexistants.